TL;DR
I created Wimmelbench, a benchmark to test how well multimodal language models can find specific objects in complex illustrations. The best model (Gemini Pro) could accurately describe objects 31% of the time but struggled with precise location marking. Models performed better with larger objects and showed varying tendencies to hallucinate non-existent items.
Introduction
I was recently reminded of old picture books I used to own. The illustrations inside were completely hand-drawn, richly detailed scenes, packed with dozens of people, overlapping objects, and multiple activities — reminiscent of Where’s Waldo, except that you’re not hunting for a particular character.
This type of illustration is called wimmelbilder, which is German for “teeming picture”.

While I’m convinced that LLMs can really “read” language, I’m less sure that they “see” images. To measure sight quantitatively, I created a small benchmark that I’m calling Wimmelbench.
Wimmelbench takes inspiration from needle in a haystack. In that benchmark, a random fact (the needle) is inserted into the middle of a large piece of text (the haystack), and an LLM is asked to retrieve the fact. Most LLMs these days score close to 100% on this task. Wimmelbench is the image analogue: a model is asked to describe a small object (the needle) in a complex scene (the haystack) and draw a bounding box around it.
The best multimodal language model I tested was Gemini Pro, which can accurately locate small objects 31% of the time. This increases to 73% if ‘mostly correct’ descriptions are also included.
The models were much poorer at drawing bounding boxes, with Gemini scoring the best at a mean GIoUGeneralized Intersection over Union. Typically a GIoU score of 0.5 and above is considered good. of 0.13 and Claude 3.6 Sonnet & GPT-4o scoring -0.5.
In this post, I’ll talk about constructing the benchmark, go into more detail on the results, and offer some analysis.
Aside: why not SAM?
Segment Anything Model (SAM) is Meta’s foundation model for promptable segmentation in images and videos. It accepts masks, points, bounding boxes — but not text — as prompts.

SAM-based models like LISA do allow text inputs like “Segment the red car in the image”. I expect that it would score well on Wimmelbench.
So why benchmark large language models?
- It tests how well the most general purpose, human-like models we have today understand images.
- I’m interested in “easy” unsaturated benchmarks that reveal a real shortcoming in current LLMs.
- I didn’t have easy access to the SAM-based models.
- It seemed like a fun project.
Benchmark construction
I collected 50 images from various sources on the internet, mostly from book storefronts and Behance. I searched specifically for wimmelbilder scenes that had a diverse range of objects and activities. They tended to be cartoonish since the style is so popular in children’s books.
To create the ground truth dataset, I (well, mostly Claude) built a web-based annotation tool, which I used to manually write descriptions and draw bounding boxes for 84 objects in 50 images. I aimed to have a range of sizes and locations for the objects.

In each description, I included the object’s location, distinguishing features, and relation to nearby objects. The annotations were saved to a JSON file.
To visualize the range of object sizes in the dataset, I plotted the distribution of each bounding box’s area as a percentage of the total image area (figure 1).
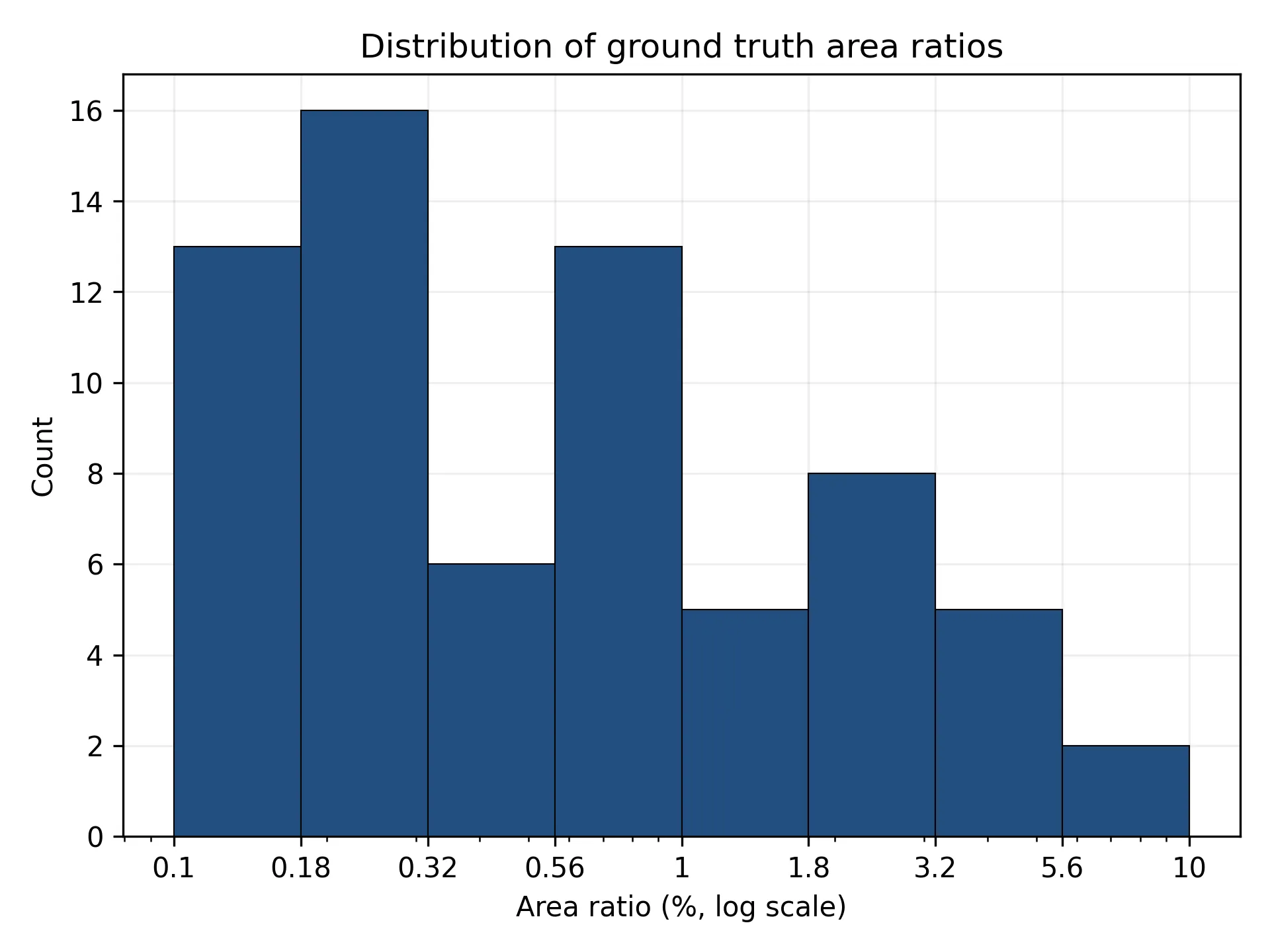
The distribution covered a range from 0.1% to 10% of the image area, with most boxes in the 0.1% - 1% range. Ideally, I’d have hundreds of boxes and a more uniform distribution, but this looked reasonable enough to begin evaluation.
Next, I asked Claude 3.6 Sonnet, Gemini 1.5 Pro, and GPT-4oSpecifically claude-3-5-sonnet-20241022, gemini-1.5-pro-002, and gpt-4o-2024-08-06. to do two things: first, describe a specific object in an image; second, return the bounding box coordinates around that object. I noted that the object may not be present in the image, so that I could later test how much models would hallucinate.
I used a slightly different promptAll prompts are available on GitHub. for Gemini because it’s been trained to return bounding box coordinates in the format [ymin, xmin, ymax, xmax] from the range . I experimented with the same format for Claude and GPT-4o, but performance was slightly worse than using the internet-standard bounding box coordinates of [x1, y1, x2, y2] with values in .
I then asked Gemini 1.5 Pro to grade the accuracy of the bounding box predictions on a scale of 0-3, where:
- 0: Completely incorrect or missing critical details.
- 1: Partially correct but missing many important details or containing significant inaccuracies.
- 2: Majorly correct with some inaccuracies or missing details.
- 3: Mostly or fully correct, capturing the majority of key details and spatial relationships accurately.
I tried using the smaller Gemini Flash, but Gemini Pro was closer to my own judgement — looking through its reasoning, I’d quibble with at most 10% of its ratings. It was also consistent in returning the same grades when run multiple times.
See the appendix for examples of bounding box predictions and grading.
You can find the full evaluation code, grading code and results in the GitHub repository.
Results
1. Description accuracy
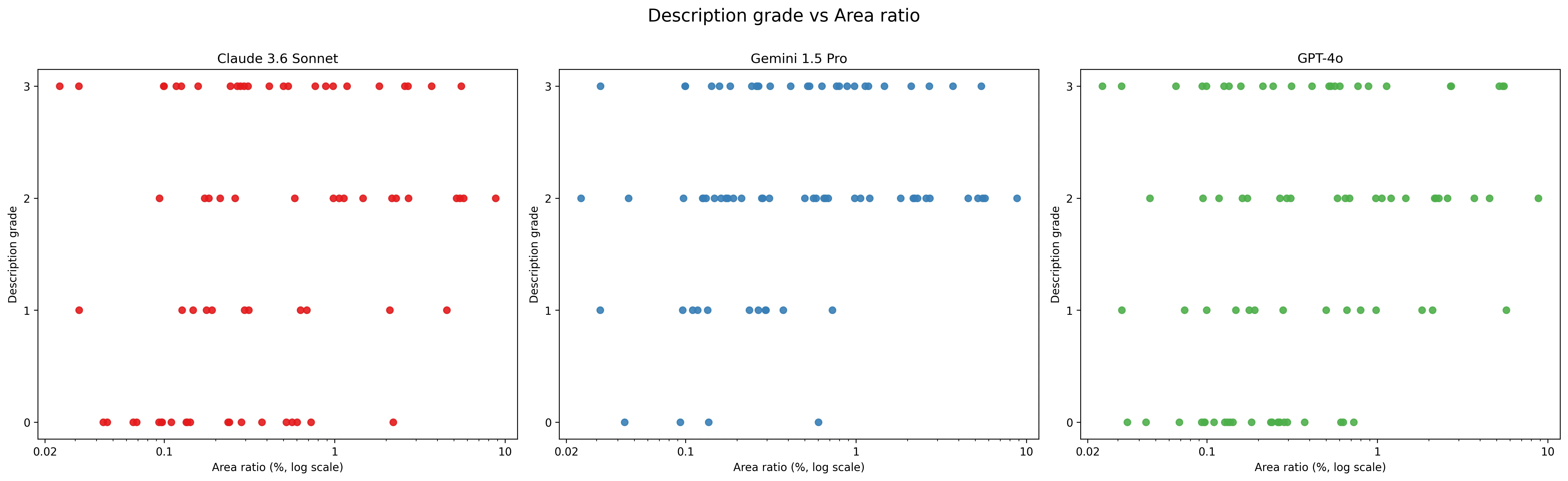
All models scored a grade of 3 for about 30% of object descriptions. If we also include the mostly correct descriptions (grade 2), then Gemini outperforms the other models, scoring 73%, compared to 55% for GPT-4o and 49% for Claude (figure 2).
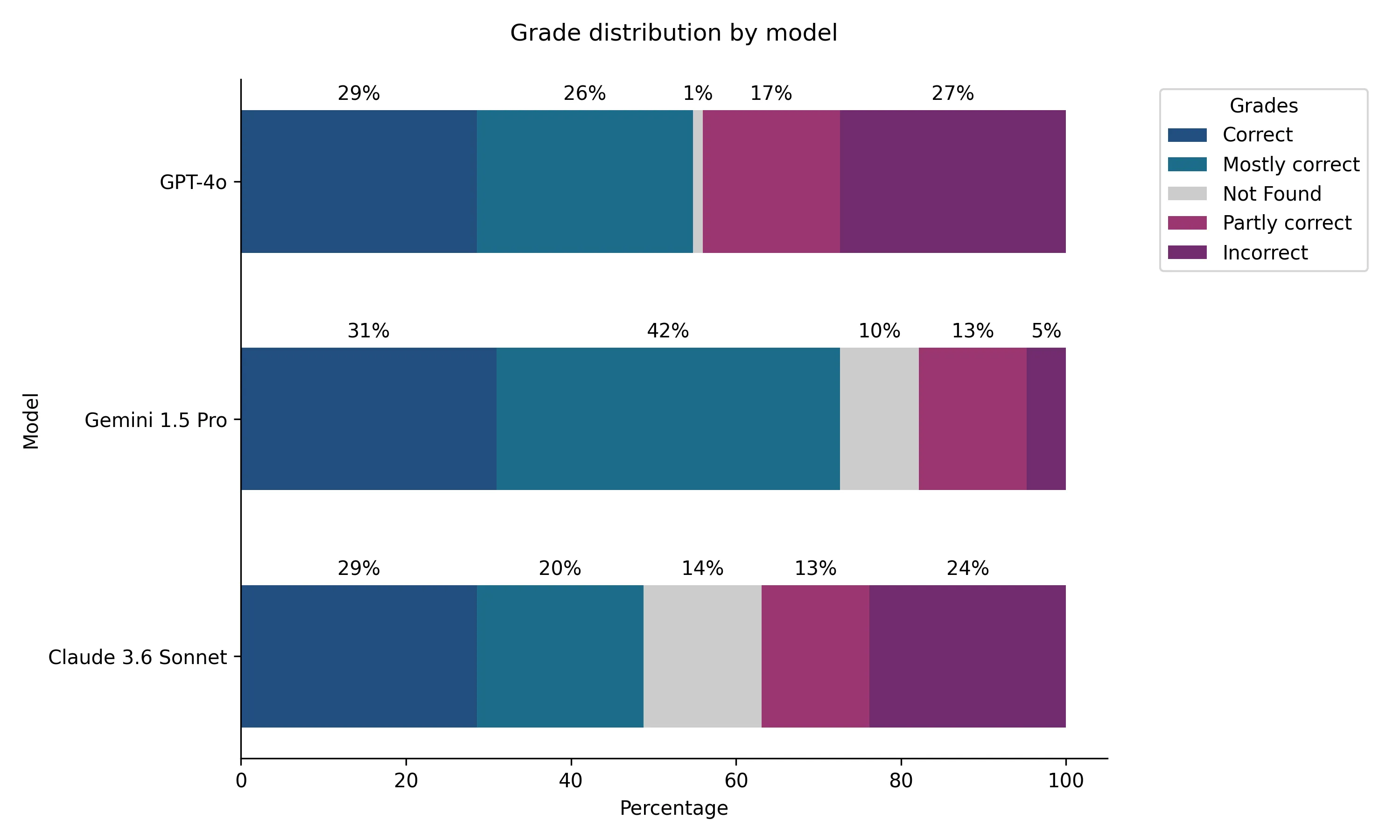
2. Bounding box precision
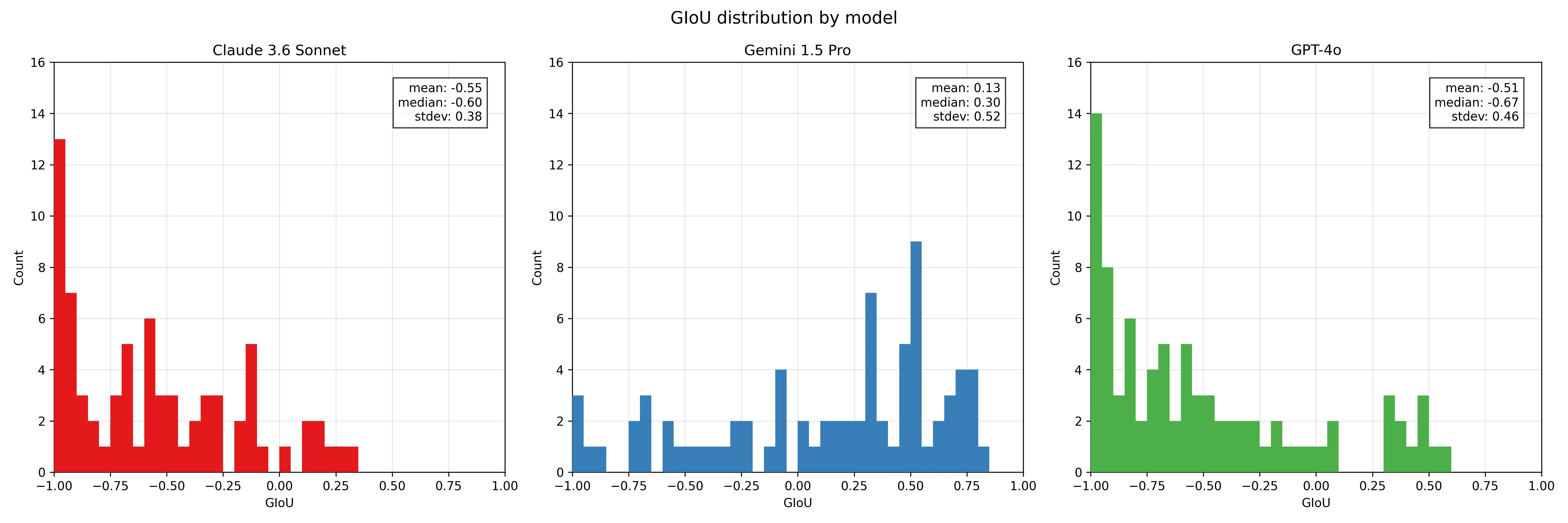
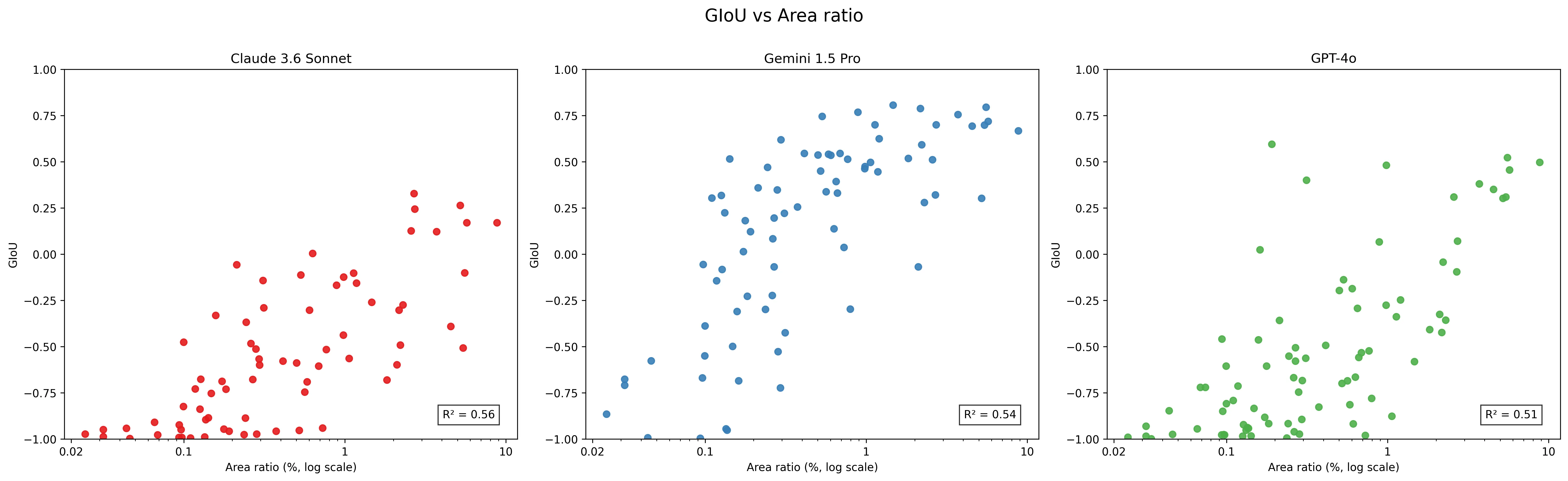
The models are much worse at predicting bounding box coordinates. For each object, I plotted the model’s Generalized Intersection over Union (GIoU), where is the smallest convex hull that encloses both and . between the predicted and ground truth bounding boxes (figure 3).
GIoU scores range from -1 to 1, where 1.0 is perfect overlap; 0.0 means no overlap; negative values indicate the predicted box is far from the target. 0.5+ is typically considered good in computer vision tasks.
Gemini Pro scores the best, with a mean GIoU of 0.13. Claude and GPT-4o score -0.60 and -0.67 respectively.
3. Hallucination rate
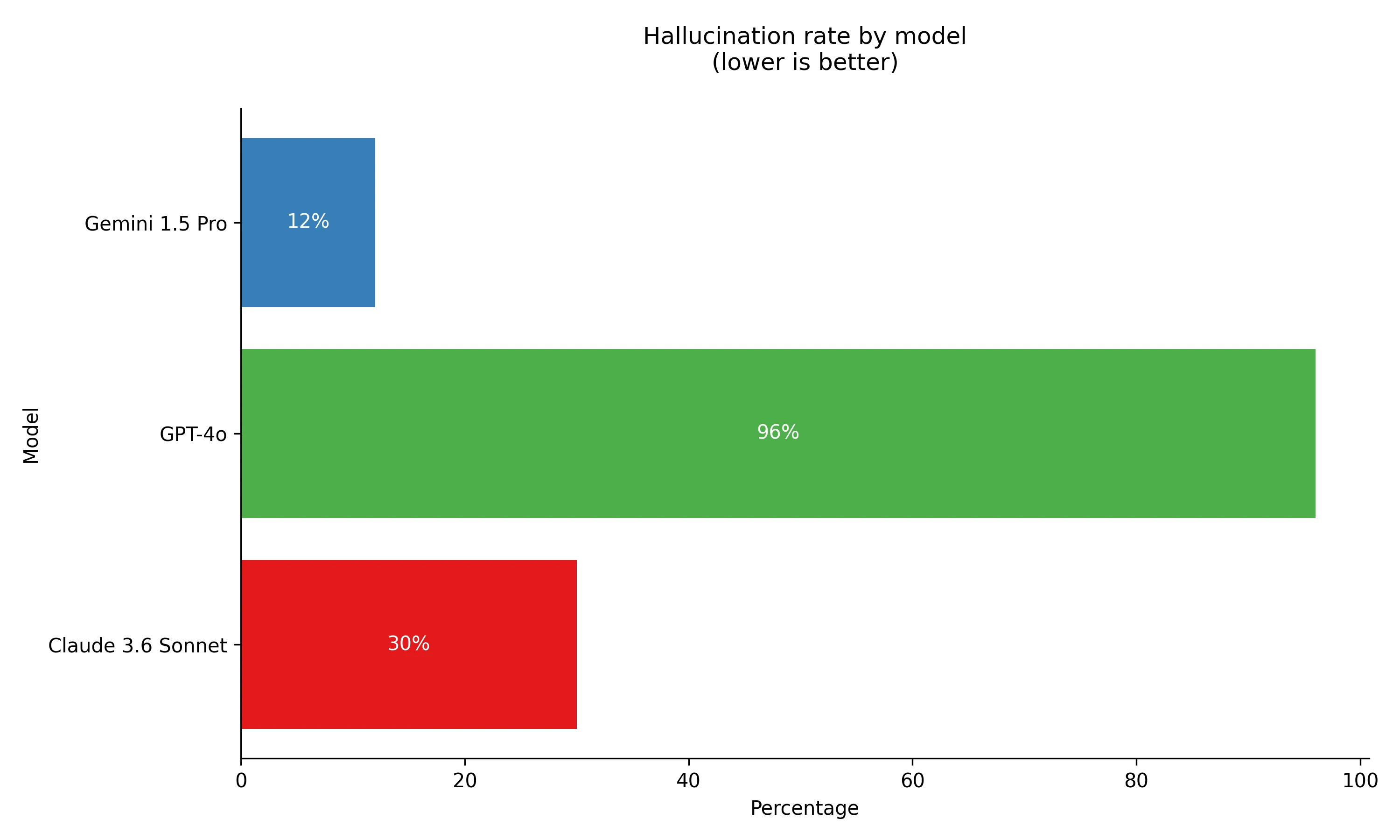
To test how much the models would pretend to see objects that weren’t there, I asked them to locate a telescope in each of the 50 images (figure 4).
GPT-4o was the biggest liar, finding a telescope in 96% of the images (!). Claude hallucinated 30% of the time, but again Gemini led the pack, only hallucinating in 12% of the images. When it did hallucinate, it tended to be with similar objects like cameras or binoculars.
Analysis
Takeaways
- Gemini Pro scores best on both description and bounding box accuracy.
- Models can often describe objects well, but struggle to locate them precisely.
- Object size strongly influences bounding box accuracy, but not description quality.
Size sometimes matters
Bounding box accuracy showed a strong correlation with object size (figure 5). was ~0.5, which means that half of the variance in bounding box accuracy is explained by object size.
Grade was much less correlated with object size (figure 6). Models seemed to struggle (and succeed) more equally to describe an object across a range of sizes.
Grade vs bounding box accuracy
Grade was only weakly correlated with bounding box accuracy (figure 7). Here Gemini showed the strongest correlation: if it was able to describe an object accurately, it would tend to draw an accurate bounding box.
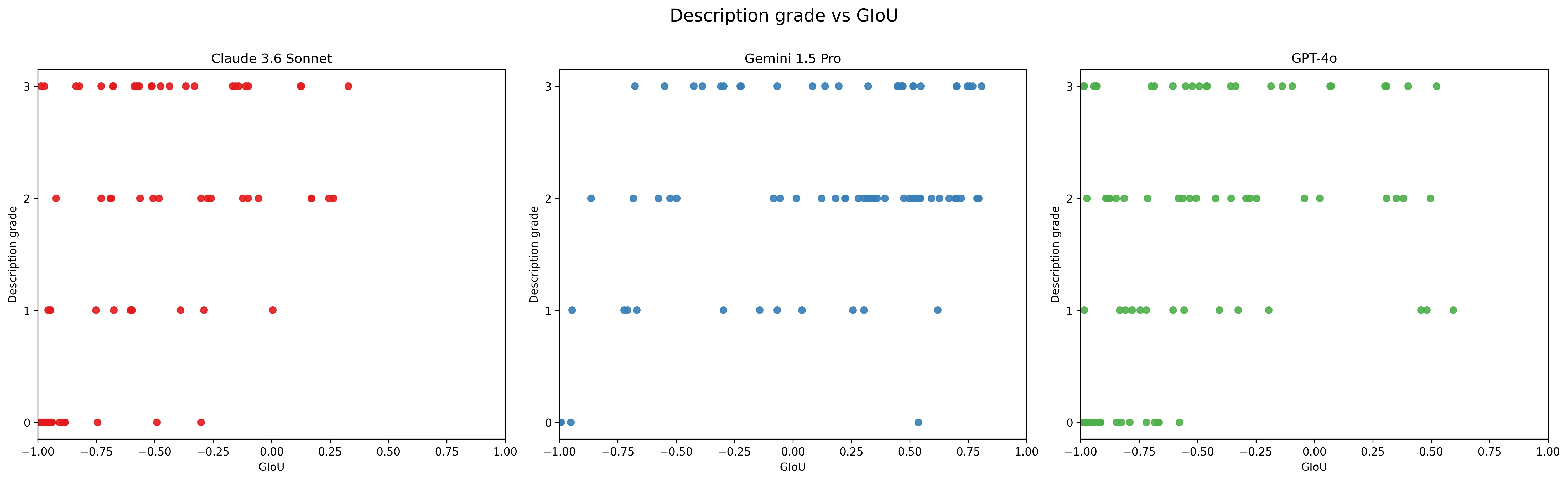
This means that a model could often describe an object in the correct place but give completely incorrect bounding box coordinates, even for large objects.

If you gave a human the same task, this wouldn’t happen — if someone could see an object, they could draw a bounding box around it. Maybe this is a prompt issue? I wouldn’t be able to guess bounding box coordinates as 0-1 ratios either, so maybe this isn’t a fair comparison. I saw a Reddit post that suggested overlaying a grid on the image and asking the model to return grid coordinates yielded better results.
Perhaps performance could also improve with additional post-training techniques. Claude with computer use is somehow able to move the cursor to a pixel-perfect location on screen, which I assume is the result of specific post-training. Similar strategies would likely transfer well to determining bounding box coordinates. Gemini’s stronger performance also suggests that there are post-training stepsFrom the Gemini docs: “For object detection, the Gemini model has been trained to provide these coordinates as relative widths or heights…” that can be taken to improve accuracy.
I don’t understand the description accuracy variance
Object size only explains half the variance in description accuracy: that is, the same object size would sometimes score perfectly, and other times completely incorrectly. For example, I was surprised at how well Gemini described the ‘couple kissing’:

On the other hand, it completely fails to find the lifebuoy in the picture below, even though it’s roughly the same size as the previous object.

I don’t understand what causes the difference in ability.
Future work
If I had more time…
- Expand the dataset to several hundred objects.
- Test with more LLMs and also specialized vision models like SAM.
- Improve prompting strategies for bounding box prediction.
Conclusion
Wimmelbench convinced me that the big lab’s language models indeed cannot see as well as they read. I suspect part of it is due to object size, part due to post-training, and part due to tokenization and model architecture. I’d love to hear your thoughts — feel free to email me.
Appendix: example results

| Object | Ground truth description | Model description | Grade | GIoU |
|---|---|---|---|---|
| Cactus | A small, green cactus is potted in the window of a light gray building on the left side of the image, near the middle vertically. In the window next to it is an orange cat. Both windows are above teal awning. | There appears to be a small green cactus in a pot being carried on a serving tray by one of the rabbit/bunny characters on the left side of the street. The bunny is one of two gray bunnies carrying food items on trays, likely heading towards the ‘EAT ME’ café in the scene. | 0 | -0.89 |
| Elephant | There is an elephant standing on two legs near the bottom-middle of the image. Its is holding a paintbrush and paint palette, wearing a purple top, and has an easel in front of it. The elephant is standing on the road. Mice are playing by its feet. Other animals are nearby. | There is a large grey elephant character sitting in the center of the street scene. The elephant is wearing a purple velvet robe or jacket and appears to be painting on a canvas that’s set up on an easel. The elephant has distinctive large ears, a long trunk, and is shown in a sitting position while engaged in artistic activity. It appears to be one of the main focal points of the busy street scene, surrounded by various other animal characters. | 2 | -0.51 |

| Object | Ground truth description | Model description | Grade | GIoU |
|---|---|---|---|---|
| Cactus | A small, green cactus is potted in the window of a light gray building on the left side of the image, near the middle vertically. In the window next to it is an orange cat. Both windows are above teal awning. | A small, green cactus is located inside the first floor window of the grey building on the left side of the image. It is positioned on the window sill. | 3 | 0.52 |
| Elephant | There is an elephant standing on two legs near the bottom-middle of the image. Its is holding a paintbrush and paint palette, wearing a purple top, and has an easel in front of it. The elephant is standing on the road. Mice are playing by its feet. Other animals are nearby. | An elephant wearing a purple robe is painting on a canvas, standing on the street, slightly left of the image’s center. The elephant is facing left and holds a paintbrush in its trunk and a palette in its left hand. A wooden easel holds the canvas. Directly to the elephant’s right, a light gray cow seems to be giving a presentation while holding a microphone. | 3 | 0.70 |

| Object | Ground truth description | Model description | Grade | GIoU |
|---|---|---|---|---|
| Cactus | A small, green cactus is potted in the window of a light gray building on the left side of the image, near the middle vertically. In the window next to it is an orange cat. Both windows are above teal awning. | The cactus is located in the bottom-right corner of the image. It is held by the giraffe and is green with several small red-orange flowers or spikes protruding from it. The giraffe is standing on the sidewalk next to a colorful group of animals. | 0 | -0.98 |
| Elephant | There is an elephant standing on two legs near the bottom-middle of the image. Its is holding a paintbrush and paint palette, wearing a purple top, and has an easel in front of it. The elephant is standing on the road. Mice are playing by its feet. Other animals are nearby. | The elephant is located slightly left of center in the lower half of the image. It is wearing a purple robe and holding a paint palette and brush, standing next to an easel. The elephant appears to be engaging in painting. | 3 | 0.31 |

| Object | Ground truth description | Model description | Grade | GIoU |
|---|---|---|---|---|
| Man waving a white flag | A man waving a white flag is in the top left of the image, by a broken a window. He is hung up on a light fixture by his jacket. To his right is a person falling, visible behind a broken window. Below him are people fighting each other. | In the far right upper portion of the chaotic scene, there is a man waving a white flag or surrendering. He’s wearing what appears to be blue clothing and is positioned near the green paneled wall. He’s surrounded by the general mayhem of the room, with other figures nearby also in various states of distress or motion. | 0 | -0.94 |
| Bowling ball | A small black bowling ball is in the middle-right of the image. It is in the air, in between two men. The man on the right has punched the man on the left who is reeling backwards. The bowling ball looks like it came off left man’s hand. | There is a black bowling ball visible in the chaotic scene, located in roughly the center-right portion of the image. It appears to be rolling or has been knocked loose during the mayhem, sitting on the wooden floor among the scattered people and overturned furniture. The bowling ball stands out as a small, round, black object amid the chaos of the cartoon scene. | 0 | -0.94 |

| Object | Ground truth description | Model description | Grade | GIoU |
|---|---|---|---|---|
| Man waving a white flag | A man waving a white flag is in the top left of the image, by a broken a window. He is hung up on a light fixture by his jacket. To his right is a person falling, visible behind a broken window. Below him are people fighting each other. | A man waving a white flag from which pieces of paper are falling is visible in the top left part of the image. He is wearing a blue suit, is seated on a short wall, and appears to be looking down at the chaotic scene below him. Behind him, one person climbs in through a broken window while another climbs out. The room has pale green walls with wood panelling. | 1 | 0.04 |
| Bowling ball | A small black bowling ball is in the middle-right of the image. It is in the air, in between two men. The man on the right has punched the man on the left who is reeling backwards. The bowling ball looks like it came off left man’s hand. | A bowling ball can be seen lying on the floor amidst the chaotic scene. It’s located slightly below the center-left portion of the image, amongst a group of people engaged in a brawl. Its color is predominantly dark gray or black. It is not in motion. It’s spatially close to a scattered pile of what appear to be pins, suggesting that it’s part of the chaotic activity in the depicted scene. | 0 | -0.99 |

| Object | Ground truth description | Model description | Grade | GIoU |
|---|---|---|---|---|
| Man waving a white flag | A man waving a white flag is in the top left of the image, by a broken a window. He is hung up on a light fixture by his jacket. To his right is a person falling, visible behind a broken window. Below him are people fighting each other. | The man waving a white flag is located in the bottom right portion of the image. He is wearing a white outfit, lying on the ground on his back, and holding a white flag up in the air. Nearby, there are people in animated poses, and the floor is wooden. | 0 | -0.98 |
| Bowling ball | A small black bowling ball is in the middle-right of the image. It is in the air, in between two men. The man on the right has punched the man on the left who is reeling backwards. The bowling ball looks like it came off left man’s hand. | The bowling ball is black and located slightly to the right of the center of the image. It is on the floor in front of a group of people who appear to be crouching or dancing. The ball is near a man who is about to step on it, creating a sense of impending comedic chaos. | 0 | -0.85 |